
Graph databases differ fundamentally from more traditional databases you may have used. They use nodes and relationships to represent and store data. This makes it easier to represent and analyse data with complex relationships. Graph databases are great for modelling supply chains, social networks, recommendation engines, and fraud detection systems to name a few. They help organisations gain deeper insights from their data.
How do graph databases work? #
To understand how they work, let's use something we're all familiar with, a table.
Below we have a table of two people containing their names and ages. The table also includes a unique ID column to identify each person (a primary key in database-speak). We’ve all seen and worked with something similar to this “people” table at work. No surprises here.
| ID | Name | Age |
|---|---|---|
| 1 | Alice | 47 |
| 2 | Ben | 32 |
But we’re not here to learn about tables. We’re here to learn about graphs! So let’s transform the table above into entries within a graph database.
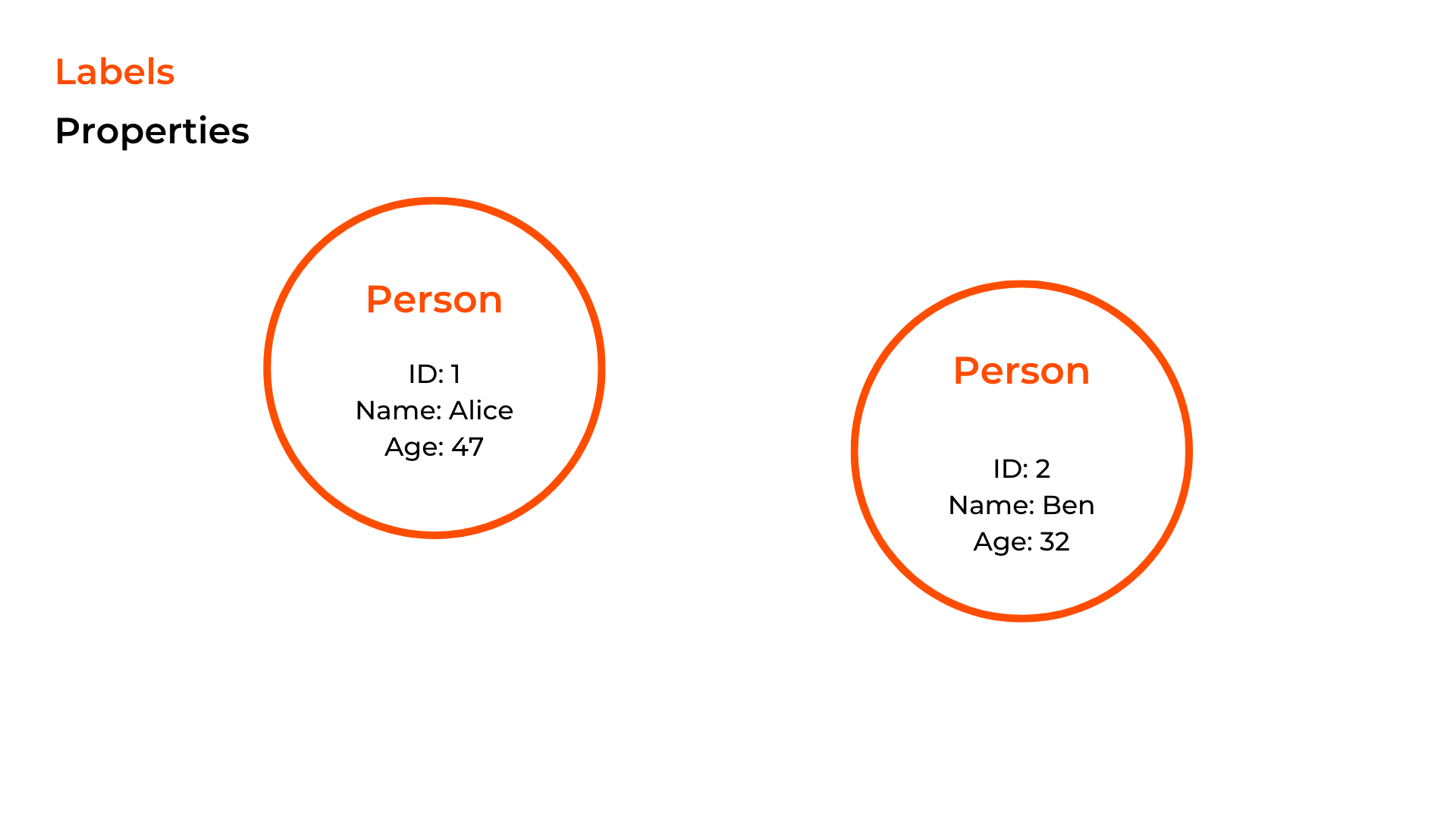
And there we have it. Two entries from our table are now two entries within a graph database. One thing to note is that these two entries are called “Nodes” within a graph database. Nodes consist of labels and properties.
When comparing our nodes to table entries, we see that the labels classify each node as a person type, similar to the table's name. The properties of the nodes describe those people, similar to the columns of each row in the table.
Perfect. We now know how to convert rows within a table to nodes in a graph database, but where are the relationships?
Good point! For that we’ll have to add an additional table, let’s call it the pets table.
| ID | OwnerID | Name | Breed |
|---|---|---|---|
| 1 | 1 | Lucky | Bulldog |
| 2 | 2 | Fred | Poodle |
Within the pets table we have two pet rows. Lucky the bulldog and Fred the poodle. Transforming these two entries into graph nodes, we get:
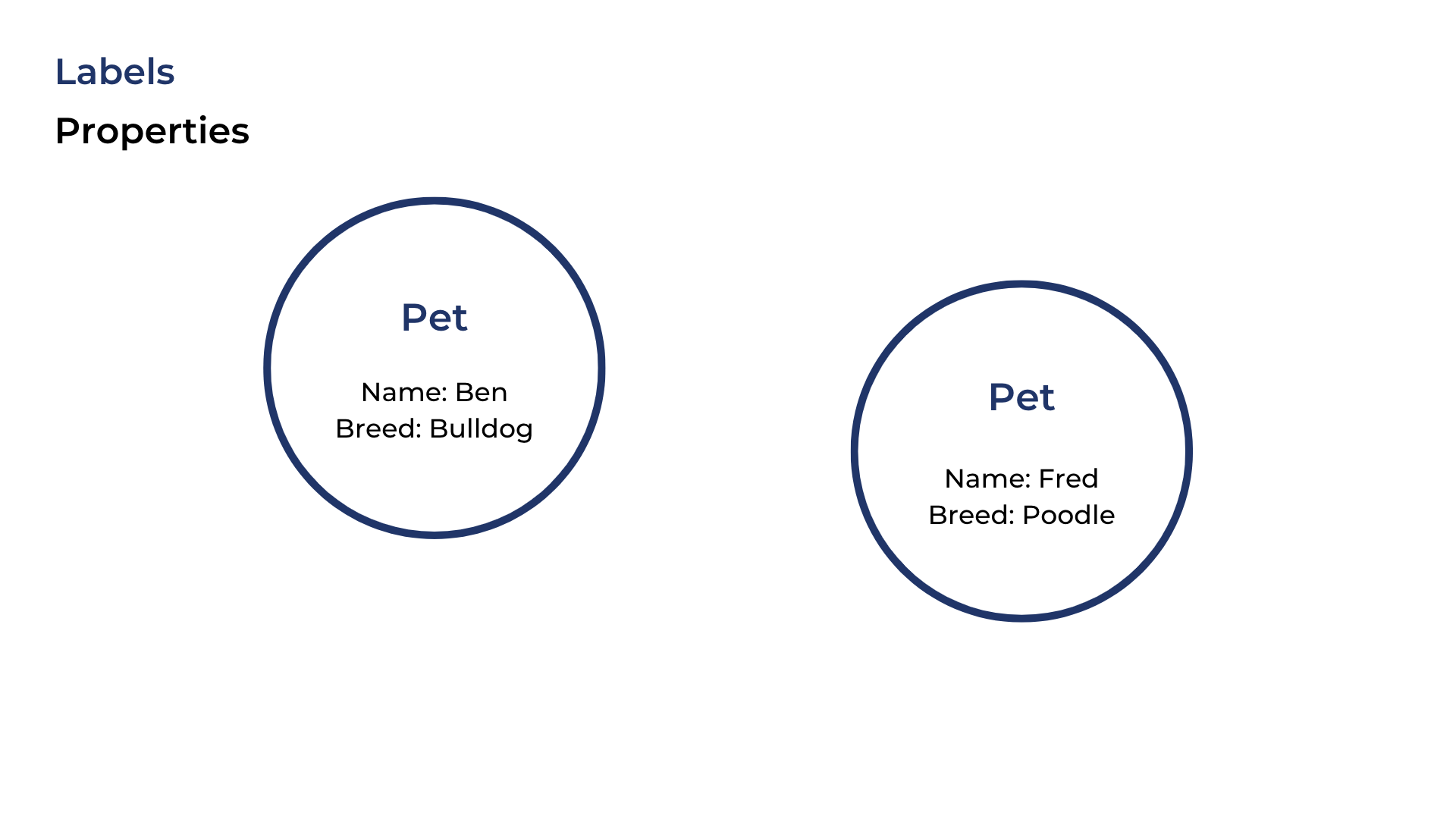
That’s great and all, but where are the relationships?
Well, we have the owner's ID available in the pets table (a foreign key in database-speak), so linking them would be as simple as:
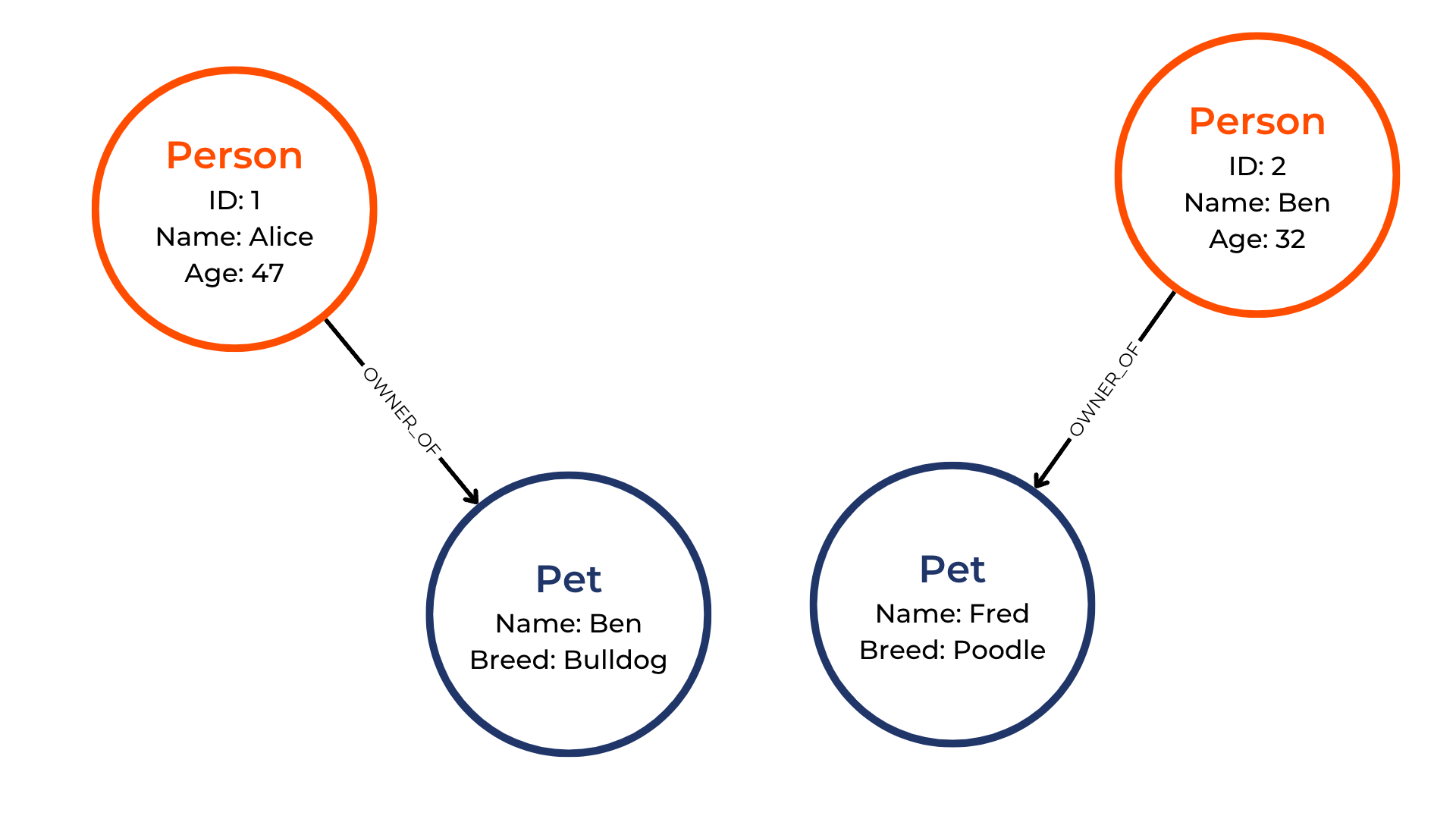
Relationships define the connection between a source (a person) and a target
node (a pet). Relationships have a type (in the above example, our
relationships are of the OWNER_OF type).
Why do we need graph databases? #
Okay, so we’ve gone through converting rows from a table into nodes in a graph database. We’ve briefly touched on how matching a foreign key from a pets table to a primary key in a people table allows us to create relationships between our nodes.
…so what?
I know, I know. Things are unclear at the moment. But we’ve made good progress. We now know that graph databases consist of two primary entities: nodes and relationships.
We also now know that we can convert data from a table into a graph containing nodes and relationships. We’re off to a great start!
However, for graphs to make more sense, we need to make things more realistic. Real-world problems are complex, and that’s what we’ll be solving using graphs. So to make things more ‘real’, we’ve made some additions to our graph:
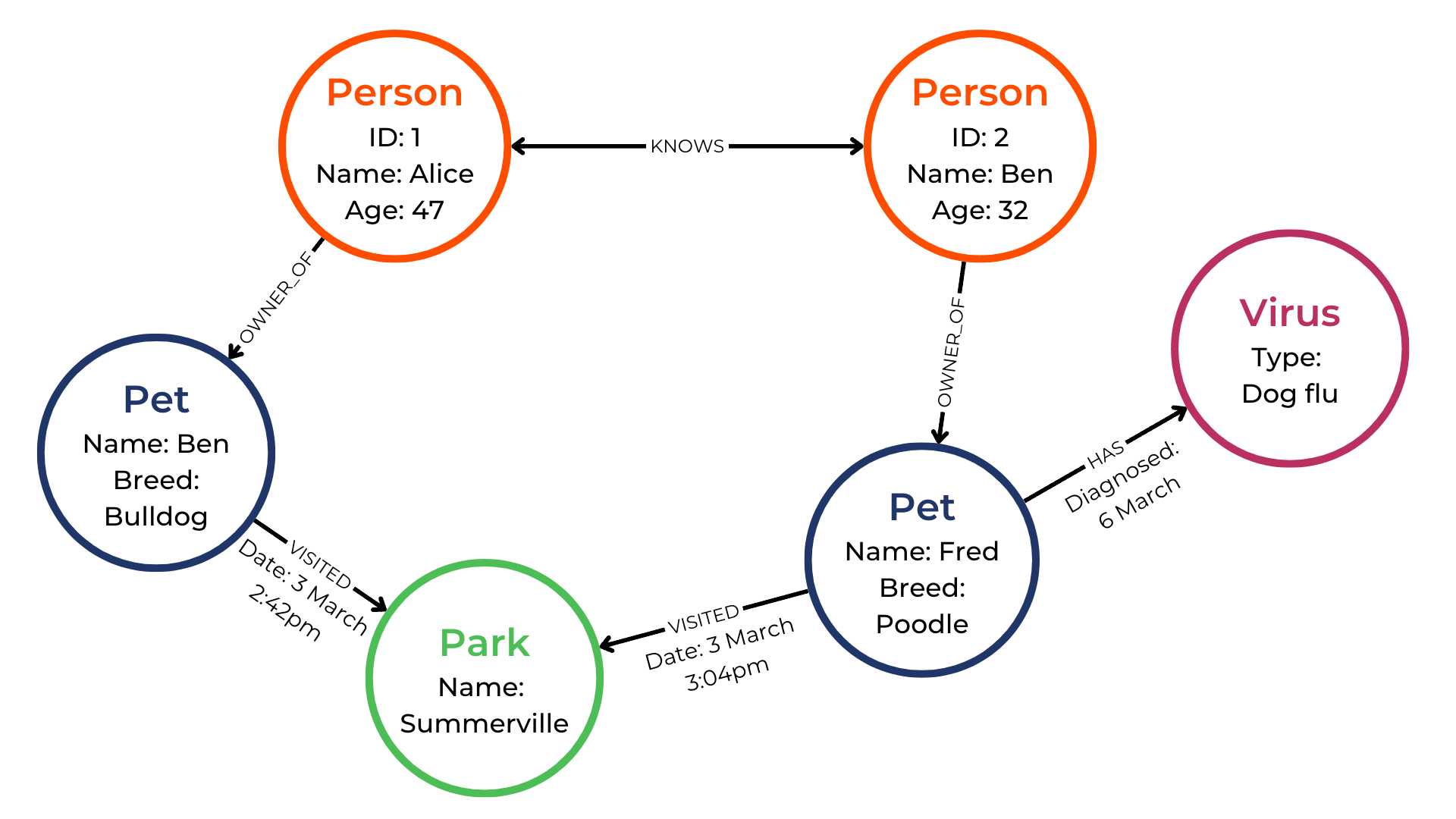
Take your time. It may seem overwhelming at first, but the scenario becomes apparent once you follow the nodes and their relationships.
The two pet owners know each other, and based on our graph, we can assume that they scheduled a meeting at their local park on March 3rd. They also decided to bring their pets, Lucky and Fred. Note that relationships can have properties as well.
But wait... Oh no! We have another node in our graph. Fred was diagnosed with a bug and the flu. Poor Fred.
However, we may be able to help Lucky!
If this were a real scenario with apps or wearables feeding data into our database, we could infer that Lucky and Fred played with each other or were in close proximity. We could then alert Alice and warn her to take Lucky to the vet, which could save Lucky from the terrible flu bug that Fred is dealing with.
This, dear reader, is where we start scratching the surface of how powerful graphs can be. By working our way through sets of nodes and relationships that describe an interaction between two friends and their pets, we can understand this story within minutes.
Graphs are clear and concise. They describe things in a way we naturally understand, allowing our conceptual model to mirror our actual physical data model.
I hope that helps with understanding why graphs are great at dealing with connected and "real" data. If we had to describe the same scenario using tables as we did with people and pets, it would take us no less than 7 tables (pets, people, parks, bugs, friends, park visits, vet visits). And we would have to manually join those tables using the primary/foreign key method. Doable. But complex.
There’s also nothing stopping me from introducing a vet node with a
VISITED relationship to a pet or a toy node with a
PLAYS_WITH relationship to a pet, or a home node with a
LIVES_IN relationship to a person. Any node, any relationship
we add will soon increase the complexity of the table method to a point
where it becomes impossible for a human brain to comprehend and extremely
computationally expensive.
However, before we completely abandon tables (referring to relational databases), we should recognise that they are still more appropriate for discrete data problems. Instead, we should look toward a future that combines the strengths of both relational and graph databases.
When should we use graph databases? #
Graphs are made to organise and store connected data, data built with relationships in mind. More traditional relational databases, on the other hand, are made to store discrete data less dependent on deep, meaningful relationships (examples include: a large list of things or a series of transactions for a payment system).
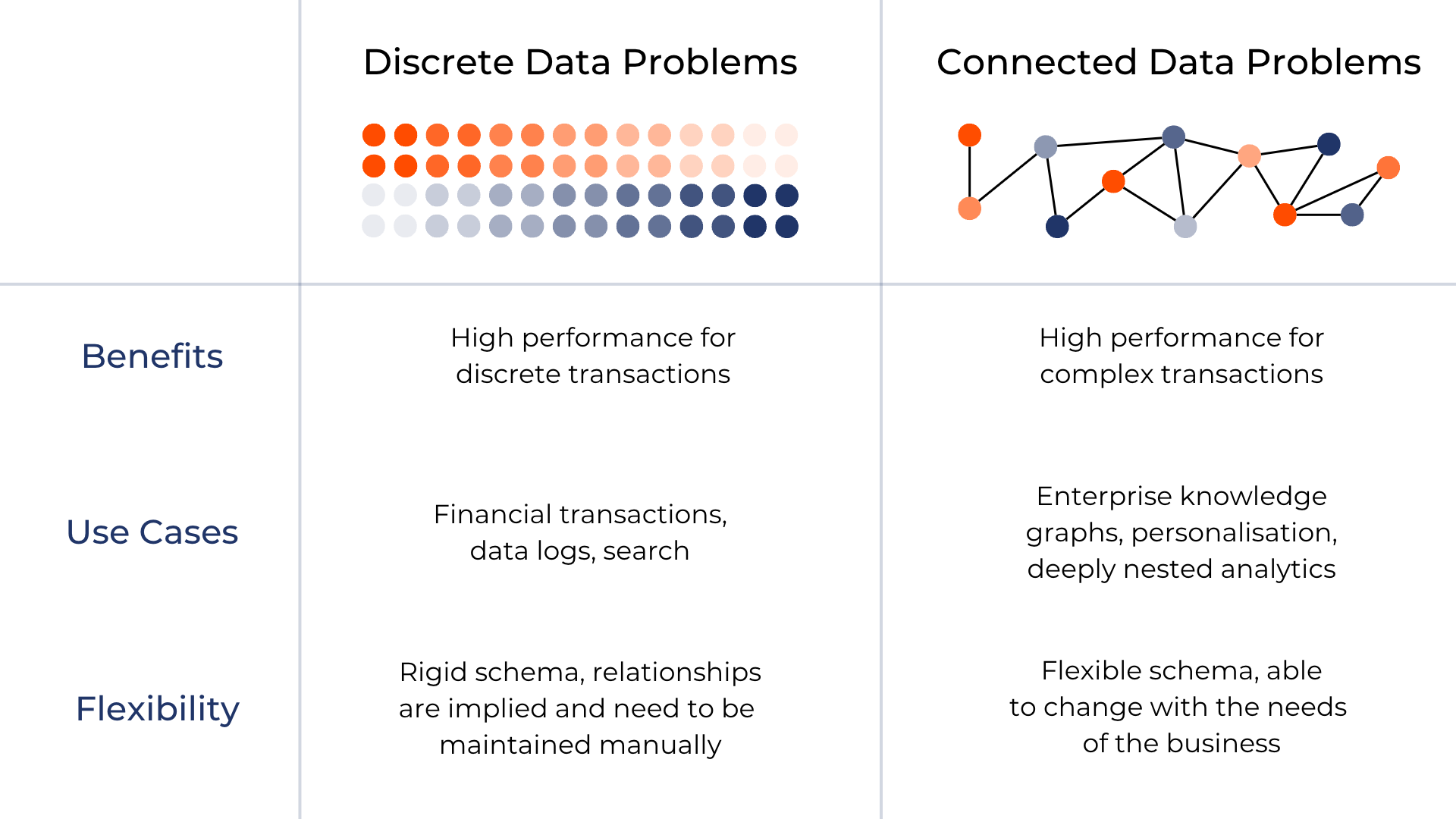
As we accelerate towards the future, the data we work with will continue to become more connected.
In our experience, one of the primary reasons architects are turning from relational to graph technologies is the shorter translation from mental models to data storage. With graph technology, you can represent both the conceptual understanding and physical organisation of your data in one image. This shorter interpretation from conceptual to physical data organisation creates a more powerful way to envision, discuss, and apply the relationships within your data. Without graph thinking and technology, this was previously unachievable.
Conclusion #
In this post we walked through the basics of graph databases and how they compare to more traditional ones. We also touched on how clear and concise graphs are once they have well-defined nodes and relationships and how we can use these to tell a story and easily unlock value that other database types may struggle to or be unable to do.
At Rockup, we believe in the power of relationships. If you think your company can benefit from a deeper understanding of the data that drives your success, contact us to schedule a free consultation call.